Snowflake는 Cloud based Data Warehouse입니다. 기존에 Oracle이나 MS SQL Server와는 달리 Index도 없고 따로 관리할 디스크나 CPU 및 Memory도 없습니다. 즉, 일체형 PC랑 비슷하다고나 할까요? Snowflake는 SaaS(Software as a Service)이기때문에 모든게 안에 포함되어 있습니다.
Snowflake의 Virtual Warehouse는 CPU 및 Memory 역할을 하고, 데이터는 Snowflake에 연결된 Cloud Storage로 저장되기 때문에 따로 관리할 필요가 없습니다. 사용한만큼만 Pay하면 되지요.
가장 큰 비용은 Virtual Warehouse의 사용료일텐데요, 최소한으로 사용하는 것이 아끼는 것일테고, 최소한으로 사용하기 위해서는 Snowflake를 어떻게 효율적으로 사용해야할지를 알아야 할 것 입니다.
이번 포스팅에서는 Snowflake의 Caching mechanism을 알아보도록 하겠습니다.
출처 : Snowflake performance tuning 교육자료
Snowflake에는 위 그림과 같이 크게 3가지의 Cache 영역이 존재합니다.
(1) Metadata : 테이블에 대한 MAX 값, MIN 값, Average 값 등이 데이터에 해당되며 Cloud Services 영역에 저장됩니다.
(2) Query Result : 한번 수행한 쿼리에 대한 결과 데이터가 저장되는 영역이며 역시 Cloud Services 영역에 저장됩니다. 결과 데이터는 쿼리를 실행한 시간으로부터 최근 24시간동안만 보관되며, 쿼리가 다시 실행되면 24시간의 시간은 다시 리셋되어 24시간이 다시 흐르게 되는 방식입니다. 쿼리가 조금이라도 달라지면 다른 쿼리로 인식됩니다.
(3) Warehouse Data Cache : 쿼리가 수행될 때마다 읽어들인 데이터를 보관하는 Cache 영역이며, 해당 Virtual warehouse가 suspend될 경우 초기화되므로 auto suspend time을 너무 짧게 설정하면 비효율적일 수 있습니다.
이전 포스팅에서 소개해드렸듯이 Snowflake는 Cloud based Data Warehouse 입니다.
제가 마침 최근에 Snowflake performance tuning 교육을 받았는데요, 아직 lab environment를 사용할 수 있으니, 이걸 이용해서 Snowflake의 기본 UI에 대해 설명해 드릴까 합니다.
로그인
본인의 혹은 회사의 Snowflake account URL로 들어가면 아래와 같이 로그인을 할 수 있는 화면이 표시됩니다.
만일 회사에서 Active directory를 사용하고 있고, Snowflake가 Microsoft Azure에 연결되어 있다면, 회사에서 사용하는 AD account를 이용하여 Snowflake에 SSO/SCIM을 설정하여 Username과 Password 없이 Sigle sign on을 하실 수도 있습니다.
여기서는 Snowflake 관리자로부터 부여받은 Username과 Password를 이용하여 로그인 하시면 되겠습니다.
UI 레이아웃
1. 상단 메뉴바 :
- Databases : 현재 Role로 엑세스할 수 있는 모든 데이터베이스 리스트와 상세 정보를 확인할 수 있습니다.
데이터베이스 목록을 확인할 수 있고, 특정 데이터베이스 이름을 클릭하면 해당 데이터베이스 안에 있는 오브젝트 목록(Tables, Views, Schemas, Stages, File Formats, Sequences, Pipes) 등의 상세 정보 또한 확인이 가능하며 오브젝트를 새로 만들거나 삭제하거나 하는 등의 관리작업도 가능합니다.
- Shares : 다른 Snowflake account의 Database를 공유 받을 수도 있고 공유할 수도 있습니다. 공유받은(Inboun) 혹은 공유한(Outbound) 데이터베이스 목록과 상세 정보를 확인할 수 있습니다.
여기 Shares에서 보이는 ACCOUNT_USAGE - SNOWFLAKE는 일종의 시스템 데이터베이스로서 어느 Snowflake account나 하나씩은 꼭 있는 Shared database이고 읽기 전용이며, Snowflake에서 일어나는 모든 기록을 여기서 찾을 수 있습니다. Oracle 데이터베이스에서의 SYS 스키마나 MS SQL Server의 master 데이터베이스와 비슷한 역할을 한다고나 할까요? SNOWFLAKE 데이터베이스의 ACCOUNT_USAGE 스키마에서 Audit history나 Query history 및 Billing history 등 거의 모든 history 정보를 확인할 수 있습니다.
- Data Marketplace : App store와 비슷한 개념으로 유료 혹은 무료의 Database 혹은 Data를 사용할 수 있습니다.
- Warehouses : 현재 Role로 엑세스할 수 있는 모든 웨어하우스(Virtual warehouses - Compute components)의 리스트와 상세 정보를 확인할 수 있습니다.
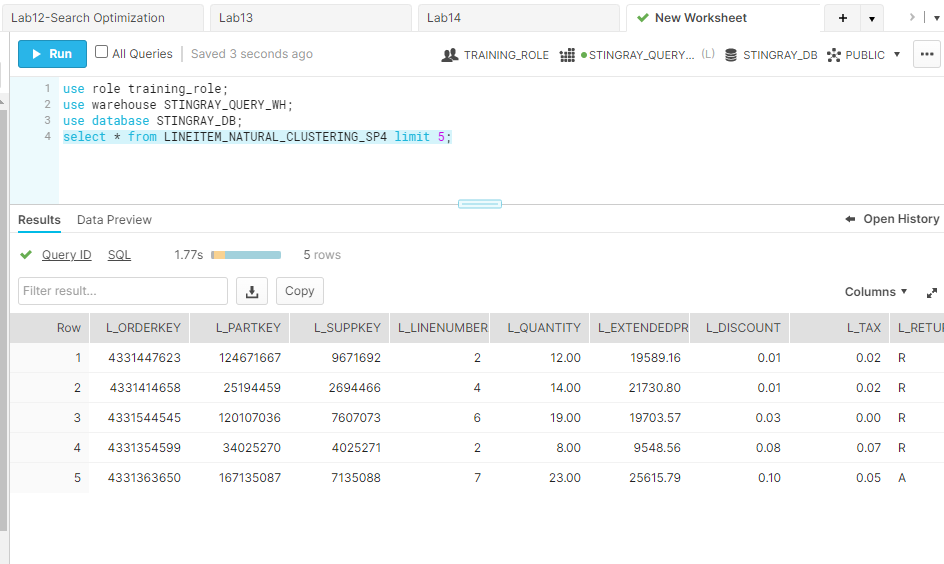
- Worksheets : 위 screenshot에 보이는 화면이며 Snowflake 데이터베이스에 쿼리를 할 수 있는 작업 공간 입니다.
- History : 과거에 수행했던 모든 쿼리의 리스트와 상세 정보 및 실행계획 등을 확인할 수 있습니다.
또한 특정 쿼리 ID를 선택하여 해당 쿼리의 실행 계획 및 통계 정보 등을 아주 자세하게 확인할 수 있습니다.
- Account : ACCOUTADMIN Role을 가진경우에만 엑세스할 수 있으며 Snowflake Accout 관련한 내용(Billing & Usage, Reader Accounts) 등을 확인하고 관리할 수 있습니다.
위 Screenshot에서는 Billing & Usage와 Reader Accounts 메뉴만 보이지만 실제 Accountadmin role을 가진 사용자가 조회할 경우 Users, Sessions, Roles, Network policies 등 더 많은 정보를 확인할 수 있으며 관리도 가능합니다.
2. 사용자 로그인 정보
아래 Screenshot과 같이 사용자 정보 오른쪽에 아래화살표를 클릭하면 Password 변경 및 Switch Role 등의 관리가 가능합니다. 여기서 보이는 Role 이름인 "TRAINING_ROLE"은 STINGRAY 사용자에게 부여된 Default role이며, 이 Role 이외에 Securityadmin, Sysadmin, Useradmin, Public role로 Switch가 가능하며 Role을 Switch 하게 될 경우 현재 UI가 약간 변경될 수 (Role에 따라 Account 메뉴가 안보일 수도 있음) 있습니다.
3. Database 탐색기
MS SQL Server의 SQL Server Management Studio의 좌측에 있는 Object 탐색기와 비슷한 기능을 하는 부분입니다. 현재 Role로 엑세스가 가능한 데이터베이스 리스트 열람할 수 있으며, 각 데이터베이스에 엑세스 가능한 스키마 및 오브젝트 또한 정보 확인이 가능합니다. 하지만, Table과 View만 볼 수 있으며 기타 Object 들 (Stages, Pipes, Procedures 등)은 여기서 볼 수 없습니다. (이게 좀 불편하긴 하던데 모든 Object 들을 볼 수 있도록 개선되지 않을까 하는 소망입니다.)
Snowflake를 처음 사용하는 사람들이 가장 많이 햇갈려 하는 부분이 오른쪽 상단에 있는 로그인 정보 부분과 이곳 세션 설정 부분에 모두 Role을 설정하는 항목이 있다는 것입니다.
오른쪽 상단에 있는 로그인 정보 부분에서 Role을 Switch하게 되면 전체 Snowflake UI에 영향을 받게 되어 전체 화면이 refresh 됩니다. 즉, Role에 따라 특정 메뉴에 엑세스를 할 수 도 있고 못할 수도 있습니다.
하지만 이 세션 설정 부분에서 Role을 Change 하게 되면 현재 "TAB"에서만 그 Role이 바뀌게 됩니다. 즉, Worksheets UI에 3개의 New Worksheet tab을 열었다면 각각의 tab에 서로 다른 Role을 설정할 수 있습니다. Role 변경은 이곳 세션 설정 부분에서 마우스로 클릭클릭하여 할 수 도 있고, 아니면 Worksheet 내부 SQL 에디터(맨 상단 Screenshot의 #5 부분)에서 다음과 같은 명령어로 Role 변경이 가능합니다.
use role securityadmin;
5. SQL 에디터 및 6. 결과 섹션
기본적인 Role change, warehouse change 및 각종 query 들을 실행하고 결과를 볼 수 있는 부분입니다. SQL Server Management Studio랑 아주 흡사하지만 다른 점도 많이 있습니다.
기본적으로 Run버튼을 누르면 커서가 있는 부분의 Query만 실행되고 전체 block을 씌우고 Run을 클릭하면 block이 씌워진 부분의 쿼리가 순차적으로 실행됩니다. Run 버튼 클릭이 귀찮으면 Ctrl + Enter를 누르면 Run을 클릭하는 것과 같은 역할을 합니다.
쿼리를 실행하면 하단의 결과 섹션에서 쿼리 결과를 확인할 수 있고 결과를 csv 파일로 download하거나 copy 버튼 클릭 후 Excel 등에 붙여 넣기 하는 것도 가능합니다.
"Query ID" 부분을 클릭하면 아래 Screenshot과 같이 해당 query id를 확인할 수 있으며, 그 query id를 한번 더 클릭하면 해당 쿼리의 query profile 을 상세히 확인할 수 있습니다.
New UI - Snowsight
Snowflake UI의 상단 메뉴 중 "Snowsight"를 클릭하면 Snowflake의 새로운 UI인 Snowsight를 사용할 수 있습니다.
Snowsight는 저도 아직 많이 써보질 않아서 소개 드릴게 별로 없고요, 나중에 제가 익숙해지면 그때 다시 소개해드리겠습니다.
저희 회사에서는 작년 여름(Summer 2021)경부터 논의가 되어 하반기부터 본격적으로 도입하여 사용하기 시작하였으며, 아직 활발한 사용은 아니지만, 조금씩 그 범위를 넓혀 가고 있습니다.
기본적인 목적은 Cloud based Data Warehouse로서 현재의 Data Warehouse on-prem으로부터 migration하기 위한 것입니다. 현재 저희 회사에서 Data Warehouse on-prem으로 Oracle 12c RAC 2-node에 40TB정도의 Storage를 사용하고 있으며, 다른 Source 시스템으로부터 여러가지 integration application을 통해 데이터를 가져와 사용되고 있습니다.
Data Warehouse의 Business application으로는 SSRS 및 PowerBI를 주로 활용하고 있으며, 팀에 따라 Excel이나 Qlik 등을 사용하는 경우도 있습니다.
재작년부터 회사의 IT방향중의 하나가 Cloud라서 가능한 모든 시스템을 Cloud base로 migration하고 있는 중입니다. Data Warehouse도 그 중에 하나이구요.
Snowflake는 SaaS(Software-as-a-Service)로서 Data Warehouse 서비스를 사용자들이 사용하기 쉽도록 제공하며, 기본적으로 Compute(CPU/Memory), Storage, 및 Analytic solution들을 사용자가 고민하지 않고 사용할 수 있도록 하고 있습니다.
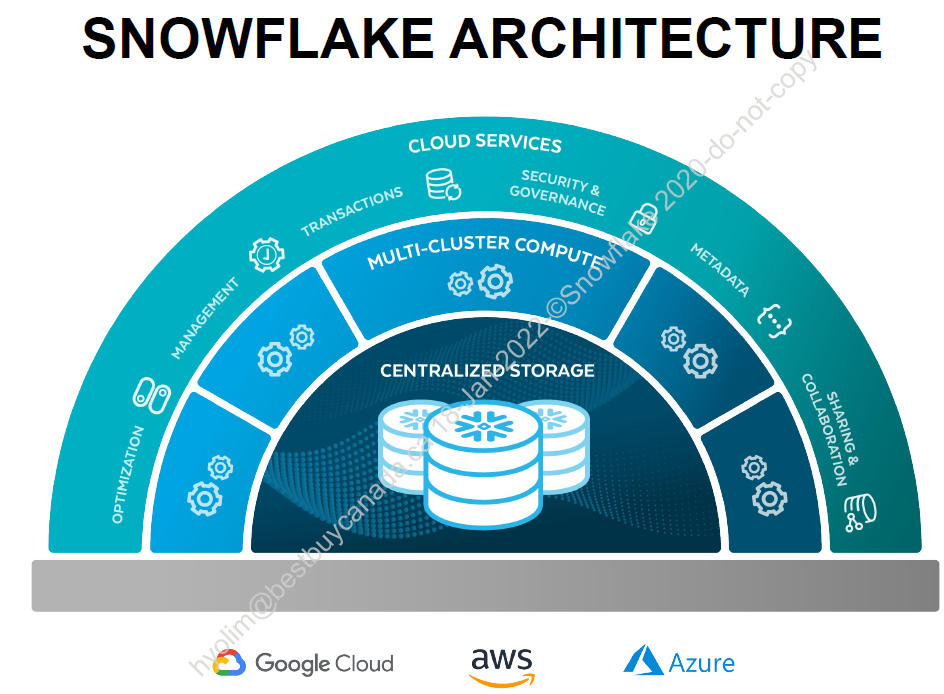
출처 : Snowflake 교육자료
Snowflake의 구조는 위 그림과 같습니다.
Storage : Snowflake에서 사용하는 모든 스토리지는 centralized되어 이곳 storage에 저장됩니다.
Multi-cluster compute : 여러개의 Virtual warehouse를 생성할 수 있으며 각각의 Virtual warehouse들은 사용 용도에 따라 Compute의 사이즈(warehouse size 및 cluster count)를 설정할 수 있으며, CPU 및 Memory의 역할을 합니다. 각각의 Virtual warehouse들은 동일한 Storage를 엑세스할 수 있습니다.
Cloud services : UI, Optimization, Management, Transactions 등 기본적으로 DBMS를 사용할 때 필요한 모든 것들을 제공합니다.
If you go to Tools menu choice then Options, you should see a Source Control on the Tree View on left.
On Plug-in Selection you should be able to choice TFS, it not then the TFS connection might have been installed before you setup SSDT. Your software keeper should be able to give you the plug-in needed to activate that.
If you are not able to choose TFS on the Plug-in Selection, you likely need to download and install Team Explorer for Visual Studio 2012 - this is the plugin that Thomas LeBlanc was talking about. Here's the download page:
The SQLOS was introduced in SQL 2000 and CLR intregration occurred in SQL Server 2005. The database engine has been stable for many releases with few fundamental changes. SQL Server 2016 includes the integration of an R language processor as an external process callable from the SQL Server database engine in much the same way that the CLR integration works. Microsoft indicated during the PASS Summit 2015 that the integration of Revolution R was done to facilitate the addition of other language processors in the future. Figure 1 shows a detailed block diagram of the SQL Server database engine architecture. We do not discuss every component in the diagram but rather focus on the areas that will help you understand the relationship between SQL Server and the storage components that it accesses during operations.
The four major components of the SQL Server architecture are: protocol layer, SQLOS, query processor (relational engine), and storage engine.
Protocol layer
The protocol layer manages the communication between clients and the database engine. .NET libraries on both the client and server computers use a Microsoft defined messaging format called Tabular Data Stream (TDS) to exchange requests and results. The protocol layer encapsulates TDS in a standard communication protocal such as TCP/IP or Named Pipes. When the TDS messages that orginate from the client are unpacked from the communication protocol, they are handed off to a command processor that is part of the relational engine. Results sets sent back to the client as TDS are unpacked and processed by the client application.
SQLOS
SQLOS is an abstraction layer that lies between the SQL Server database engine, Windows and any external components such as the CLR and the R language processor. It is responsible for functions including thread scheduling and memory management typically performed by Windows for other applications. SQLOS does not have any abstration for I/O requests. Threads used by SQL Server issue mostly asynchronous read and write requests directly to Windows and then wait for the results. The SQLOS queries Windows at startup to detemine the number and type of CPUs (NUMA, non-NUMA). It uses this information to create theads and schedulers to handle multiple simultaneous requests while it hides the details from Windows to prevent unnecessary context switching for long running processes. The database engine constantly communicates with Windows through the SQLOS to request and respond to memory allocation adjustment requests. Windows is responsible for negotiating memory allocations for all processes running on the server and makes adjustments based on requrests from applications as well as its own needs and the total amount of memory available to Windows. Windows grants memory requests from SQL Server as long as there are sufficient available memory resources on the server. If Windows receives more requests for memory than it can grant, the OS may try to negotiate with SQL Server to reduce the amount of memory allocated. The SQLOS manages its memory resources dynamically in negotiation with Windows using an internal object called the buffer pool. All memory in the buffer pool that is not used by an internal process such as the procedure cache or client connections, and so on, is allocated to a data cache used by the storage engine for buffering data and index pages. The data cache is typically the largest consumer of memory from the buffer pool. The SQLOS uses a memory broker to efficiently adjust memory allocations from the buffer pool to the many internal services that need dynamic memory allocations.
Query processor
The Query Processor, shown in Figure 1, is also referred to as the relational engine. The main responsibilites of the relational engine are:
Validating T-SQL statements.
Parsing SQL statements by breaking them down into keywords, parameters, operators, and identifiers, and creating a series of smaller logical operations.
Optimizing the execution plan, which consists of finding an acceptable plan from the list of candidate plans that it determines can perform the tasks required. The relational engine estimates the cost of the processing steps based on internal metrics including estimated memory usage, CPU utilization, and the number of required I/Os based on statistics for a set of competing plans until further optimziation is determined to be more expensive than execution. The optimizer does not guarantee that the selected plan is the best but is good enough to indicate that further optimization is not warranted. Plans that are used from cache and plans that are considered trival require optimization.
Processing Data Definition Language (DDL) and other statements, such as SET statements, to set connection options and the CREATE statements to create objects in a database.
Formatting results returned to the client. The results are formatted as either a traditional, tabular result set or as an XML document. The results are then encapsulated in one or more TDS packets and returned to the application.
Storage engine
The SQL Server storage engine interacts with the relational engine to provide services to end users. From the perspective of the user and the DBA, the functioning of the storage and relational engines are indistinguishable. However, for IT professionals who design and manage applications, a basic understanding of these internals can be instrumental in understanding SQL Server behavior and problem troubleshooting.
The main functions of the storage engine are:
Managing the data cache buffers and I/O to the physical files
Controlling concurrency, managing transactions, locking, and logging
Managing the files and physical pages used to store data
Recovering from system faults
The relational engine decides which data satisfies a request and the storage engine makes the data available. The storage engine is also responsible for maintaing data integrity to prevent simulaneous requests from interfering with each other.
This high level time line shows how the relational engine and the storage engine work together to satisfiy a request:
Data access activity begins with a query, whether it originates from a user interface or from an automated task. The data request is passed from the protocal stack into the relational engine.
The relational engine compiles and optimizes the request into an execution plan. The plan consists of a series of steps that is required to retrieve and process the data into a result that the client can consume.
The relational engine runs the execution plan. The execution steps that involve accessing tables and indexes are sent to the storage engine.
The storage engine returns data to the relational engine where it is combined and processed into the final result set and returned to the protcol stack.
The result set is sent back to the user via the protocol stack.
SQL Server logical components
The SQL Server database engine was originally designed to effectively support normalized database design. A number of enhancements, especially in the last few releases, have greatly improved performance for data warehouse workloads which are typically de-normalized.
Normalization is the process of removing redundancies from the data. Transact-SQL queries then recombine the table data using relational join operations. By avoiding the need to update the same data in multiple places, normalization improves the efficiency of an application and reduces the opportunities to introduce errors due to inconsistent data. The SQL Server logical architecture defines how the data is logically grouped and presented to the users. The core components in this architecture are:
Tables: Tables consist of one or more data pages. The table columns define the number and type of data that may be stored in the table. Each instance of the columns is stored as a row. The rows of a table may be ordered on the data pages and stored on disk according to the value of a clustered index key. Tables that do not have a clustered index key are stored on pages and disk in an unordered structure, also known as a heap. The storage of tables with a clustered index uses a binary tree or b-tree structure.
Indexes: A non-clustered index defines a key value made up of one or more columns of a table and stored as a b-tree. Additional data from the table that is not part of the index key can also be included in the b-tree. An index can speed up access to data when the data can be searched for by the value of index key. Additional performance gains can be attained if all the data required by the query is contained in the leaf of an index as either part of the key or non-key included columns. This prevents the relational engine from performing an additional lookup from the parent table. Indexes require additional storage and maintenance that can be non-trivial and can adversely impact Insert, Update, and Delete performance. Indexes that are rarely or never used by the optimizer have costs with no corresponding benefit.
Views: A view is a virtual table or a stored query. Views primarily assist application developers by reducing the number and complexity of queries to retrieve commonly accessed data that requires multiple tables to be joined, sorted and or filtered. A view may also be indexed and potentially used by the optimizer to speed up data access.
Stored procedures: A stored procedure is a group of Transact-SQL statements compiled and stored in a single execution plan. Coding business logic into stored procedures creates a single point of control to ensure that business rules are correctly enforced. The use of stored procedures and proper parameterization is considered a best practice because of the execution plan efficiency, and prevention of SQL Injection Stored procedures can also improve performance through the reuse of cached execution plans. SQL Server has an efficient algorithm to find any existing execution plans for any specific SQL statement. Cached execution plans can become stale or not be optimized for all values of user supplied input parameters. There have been enhancements to how parameters are treated for cached plans such as optimize for unknown optimizer hint. SQL Server provides SQL Server logical components numerous performance monitor counters and dynamic management views that you can access to determine if your stored procedures affect performance positively or negatively.
Constraints: Constraints are commonly used to enforce data integrity in a database including referential, data, and unique keys or indexes.
User-defined functions: Like functions used in other programming languages, SQL Server supports user-defined functions as named routines that accept parameters, perform an action, such as a complex calculation, and return the result of that action as a value. The return value can either be a single scalar value or a result set.
Triggers: A trigger is a stored procedure that automatically executes when an event occurs in the database server. DML triggers execute when a user tries to modify data through a data manipulation language (DML) event. DDL triggers execute in response to a variety of data definition language (DDL) events. These events primarily correspond to Transact-SQL CREATE, ALTER, and DROP statements, and certain system stored procedures that perform DDL-like operations.
Not all database designs follow strict normalization rules. A database that is used primarily for decision support (as opposed to update-intensive transaction processing) may not process many redundant updates. The database structure may be more understandable and efficient for decision support queries if the design is not fully normalized. De-normalization can also help the query optimizer be more efficient for typical data warehouse queries.
The impact of database design on performance cannot be overstated. Databases that are not normalized are a more common design problem for OLTP workloads than having data structures that are over-normalized. Starting with a normalized design and then selectively de-normalizing tables for specific reasons may be the best strategy.
SQL Server physical components
The SQL Server physical components determine how the data is stored in the file system of the operating system. The selection of the number and types of table columns and index design has a major impact on the requirements for physical storage.
Database file types
SQL Server uses three types of files:
Primary data files: Every database has one primary data file that stores data as well as information about other files used by the database.
Secondary data files: A database can have zero or more secondary data files. Secondary data files are not required, and a database can have many secondary files or none. By convention, a secondary data file has an .NDF extension.
Log files: Each database has at least one or more log files independent of the number of data files. Log files store the write ahead transaction log information that is needed to recover transactions for the database. By convention, a transaction log file has an .LDF extension.
Data files
Data files store the 8K pages used by SQL Server. A SQL Server page is the basic unit of logical data storage. A page begins with a 96-byte header that contains system information about the page. The disk space allocated to the primary or secondary data files (MDF or NDF) is logically divided into pages.
The most common types of pages that can be allocated to a data file are:
Data pages
LOB pages
Index pages
Page free space (PFS) pages
Global allocation map and shared global allocation map (GAM and SGAM) pages
Index allocation map (IAM) pages
Bulk change map (BCM) pages
Differential change map (DCM) pages
Figure 2 shows the relationship of these major page types in a data file:
Extents
Extents are the basic units for allocation of space. Each extent has eight physically adjacent pages (64 KB). A new table or index is usually allocated pages from mixed extents. Uniform extents are used for subsequent allocations after the object grows beyond eight pages.
Some SQL Server features use extents. For example, database snapshots allocate new space in their associated NTFS sparse files using extents, even if only one page in the extent has changed. This allows SQL Server to put pages for subsequent changes from that extent in an adjacent location on disk to improve performance when reading from the sparse file. Also, when using differential backups, SQL Server uses the differential change map pages in the data file to identify any extents that have been modified since the last full back. The backup engine then copies those changed extents to the differential backup file. On restore, the full backup is used to create a new copy of the database and then changed extents that are stored in the differential backup are used to overwrite the extents from the full backup that have changed.
File groups
Every database has a PRIMARY file group. Most databases have only the PRIMARY file group and one data file. User-defined file groups can be created to group data files together for administrative, data allocation, and placement purposes. A file group can contain one or more data files.
At any time, one file group is designated as the default file group. When objects are created in the database without being assigned to a file group, they are assigned to the default file group. The files in the default file group must be large enough to hold any new objects not allocated to other file groups. The PRIMARY file group is the default file group unless it is changed by using the ALTER DATABASE statement.
Historically, when SQL Server was deployed on servers that had a limited number of direct-attached disks, DBAs used multiple file groups and files to spread I/O across physical disks. It was common to create large tables and their corresponding indexes on different file groups so that the files could be allocated to different physical disks.
With the widespread adoption of RAID controllers and intelligent storage arrays, the added complexity of such detail object placement does not lead to better performance. There are, however, several reasons to use multiple files and file groups for a database including:
Use of In-Memory tables requires the creation of a Memory Optimized file group.
Filestream requires a filestream file group.
Create multiple equal sized files in one file group because of a high page allocation rate. SQL Server will spread new allocations for objects created this way using a proportional fill algorithm. This technique is widely used for TEMPDB data files for instances that have high object creation and deletion rates. This can alleviate wait times associated with page latch waits on the data file allocation pages. It can also be necessary for user databases that have similar characteristics.
Separate table and index partitions into read/write and read-only file groups for data warehouse applications. Read-only file groups only need to be backed up once. Subsequent backups can ignore the read-only file groups because that data does not change.
SQL Server Enterprise Edition includes a feature that allows for piecemeal recovery of the database using multiple file groups. On restore, SQL Server Enterprise Edition can make the database available after the primary file group has been brought online. The other file groups can be brought online in any order.
Use file group for partitioned table management. Partitions can be assigned to different file groups using different classes of storage. Partitions can be switched in and out of the table for better data loading and archiving.
Transaction logs
The transaction log records changes made to a database and stores enough information to allow SQL Server to recover the database. Recovery reconciles the data in the data files with changes recorded in the transaction log. The recovery process happens every time the server instance is restarted and optionally when a database or log restore occurs.
Physically, the transaction log consists of one or more files configured as a “circular log”. If multiple log files exist you can think of them as being a single concatenated space. There are no parallel log operations when multiple files are used and typically no performance advantages. The use of multiple log files usually occurs when the existing log file needs to be extended but there is no allocated space on the Windows device. By adding another log file, the additional space is available to the log writer.
The buffer manager in the storage engine guarantees that the log file will be written to before the change is made to the database (called write ahead logging). Writes to the log are asynchronous, however, the storage engine must receive a successful response from the log write operation at the end of a transaction before acknowledgement is made to the client that the request was successful. The log write buffer can hold up to 60K of log data. The buffer is flushed at the completion of each transaction or when the buffer is full, whichever occurs first.
Information in the log is stored in variable length records that are uniquely identified by a Log Sequence Number. The log file contains information regarding:
The start and end of each transaction
Data modifications
Extent and page allocations and de-allocations
Creation and elimination of a table or index
Each log file consists of a number of virtual log files based on the initial size of all transaction log files and the growth increment set for auto expansion. Virtual log files are the smallest unit of truncation for the transaction log. When a virtual log file no longer contains log records for active transactions, it can be truncated and the space becomes available to log new transactions. Figure 3 shows how circular logging uses multiple virtual logs in a single physical file.
Source : Microsoft SQL Server Best Practices and Design Guidelines for EMC Storage Solution Guide - Part number H14621 (December 2015, EMC Corporation)
Database : Oacle 11.2.0.4 Standard edition OS : Windows Server 2008 R2 64x
At this morning, our application got this error message.
"Can not change status:ORA-04029: error ORA-7445 occurred
when querying Fixed Table/View ORA-06512: at
"SYS.DBMS_ALERT", line 78 ORA-06512: at
"SYS.DBMS_ALERT", line 102 ORA-06512: at
"LIMS.UTILITY_PKG", line 254 ORA-06512: at line 2"
When I got this error message from our BA, I had no idea about the DBMS_ALERT package. But after reviewing the DBMS_ALERT part in Oracle database manual, I guessed that DBMS_ALERT package uses a kind of message queue, and the queue has been pending status in some unknown reason.
So I tried to clear the pending status message with the following command;
SQL> EXEC DBMS_ALERT.REMOVEALL;
or
SQL> EXEC DBMS_ALERT.REMOVE(' <Name of the Alert>');
You can find the name of the alert using this command;
-- Create Test DB CREATE DATABASE [DBName] GO -- Take the Database Offline ALTER DATABASE [DBName] SET OFFLINE WITH ROLLBACK IMMEDIATE GO -- Take the Database Online ALTER DATABASE [DBName] SET ONLINE GO -- Clean up DROP DATABASE [DBName] GO
SQL Server 2016 has improved the HA/DR solution - AlwaysOn, and also adds this great feature in Standard Edition with some limitation. AlwaysOn in SQL Server 2016 Standard Edition is very similar with the mirroring feature which was deprecated on SQL Server 2012.
This is the some limitation of AlwaysOn in SQL Server 2016 Standard Edition.
Actually, SQL Server 2016 is not released yet. Current released version is SQL Server 2016 RC3(April 15, 2016), and it has only Evaluation(Enterprise), Developer, and Express Edition. So I couldn't confirm the limitation of this feature on Standard Edition.
So I just would like to introduce you how to install and configure the AlwaysOn Availability Group with SQL Server 2016 Evaluation Edition.
1. Set up Windows Failover clustering
The big difference between mirroring and AlwaysOn is the Failover clustering. Mirroring doesn't use it, but AlwaysOn use it. Let's get started to install the Failover clustering on Windows Server 2012. SQL Server 2016 support Windows Server 2012 or higher version.
Install Failover clustering feature on the first node.
And do same thing on the second node.
Then open the Failover Cluster Manager on any node.
Click Validate configuration.
Add nodes to join this new cluster.
After finish this validation, please review carefully the report if there is any error message.
Now it's time to create new cluster if there is no error message on the report.
AlwaysOn doesn't need any shared disk on the Failover clustering, so when new cluster is created, "Add all eligible storage to the cluster" should be unchecked.
When the cluster creation is finished, the Failover Cluster Manager will look like this.
2. Install SQL Server 2016 RC3
It's same as previous version. SQL Server 2016 doesn't need .Net Framework 3.5. Instead, it uses .Net Framework 4.0.
SQL Server 2016 installation image doesn't have SQL Server Management Studio(SSMS) and SQL Server Data Tools(SSDT). These tools need to be downloaded separately. If you click "Install SQL Server Management Tools", the installer will open the web browser so you can download the tool.
This is new SQL Server Management Studio. Its theme looks like Visual Studio 2012.
3. Set up AlwaysOn Availability Group
First, enable AlwaysOn Availability Groups on SQL Server service's properties.
I will configure AlwaysOn on the database "AG_Test".
If the second node doesn't have same database on the instance, SQL Server 2016 will create same database during the configuration of AlwaysOn. But if the database is huge, the AlwaysOn configuration time will be quite long. So I backed up this database on the first node and then restored it on the second node.
Create new Availability Group on the first node.
The target database is already copied and restored on the second node, so "Join Only" will be chosen. If you don't have the same database on the second node, "Full" should be selected.
Now it's done!
When you see the Availability Group's Dash board, it will look like this.
Reference : Introducing Microsoft SQL Server 2016 Preview2 - Stacia Varga, Denny Cherry, Joseph D'Antoni